
বেশিরভাগ স্ব-শিক্ষিত প্রোগ্রামারদের মতো, আমি আমার অনেক বছর বিভিন্ন প্রযুক্তির সাথে ড্যাবল করে কাটিয়েছি। কিন্তু প্রত্যেক প্রোগ্রামারের জীবনে একটা সময় আসে যখন তাদের কর্মজীবনে এগিয়ে যাওয়ার জন্য ডেটা স্ট্রাকচার এবং অ্যালগরিদম শিখতে হয়। এই পোস্টে, আমি ডেটা স্ট্রাকচারের বেসিক বিষয়গুলো, তারা কী উদ্দেশ্য সার্ভ করে এবং তাদের মধ্যে কী কমন তা দেখাবো৷
একটি ডেটা স্ট্রাকচার হলো একটি কম্পিউটারে বাস্তব জীবনের ডেটা সংগঠিত করার একটি বিশেষ উপায় যাতে এটি কার্যকরভাবে ব্যবহার করা যায়।

ডেটা স্ট্রাকচার বোঝার জন্য, আমাদের প্রথমে ডেটা বুঝতে হবে। প্রতিটি প্রোগ্রামিং ল্যাঙ্গুয়েজে, আমাদের কিছু ডেটা টাইপ রয়েছে। কিছু প্রোগ্রামিং ল্যাঙ্গুয়েজে, আমাদেরকে ‘int’, ‘float’, ‘bool’, ‘char’ ইত্যাদির মতো কীওয়ার্ড ব্যবহার করে ডাটা টাইপ প্রকাশ করতে হয়। আমরা পাইথন এবং জাভাস্ক্রিপ্টের মতো ল্যাঙ্গুয়েজে সেগুলো দেখতে নাও পেতে পারি কিন্তু তারা এখনও এক্সিস্ট করে। তারা জাস্ট প্রোগ্রামার এর চোখ থেকে লুকানো থাকে। ইন্টারপ্রেটার আমাদের জন্য সেগুলো হ্যান্ডেল করে এবং এই আচরণটি ল্যাঙ্গুয়েজের ফিচার হিসাবে গণনা করা হয়।
Primitive Data Types and Memory
আমাদের অবশ্যই বুঝতে হবে যে প্রতিটি ডেটা টাইপের জন্য অপারেটিং সিস্টেমটি RAM এ একটি নির্দিষ্ট পরিমাণ মেমরি বরাদ্দ করে। আমাদের দশমিক সংখ্যা পদ্ধতিতে, যেখানে একটি স্থান 10টি স্বতন্ত্র ভ্যালু (0 থেকে 9) ধরে রাখতে পারে, বাইনারি সংখ্যা পদ্ধতিতে, একটি স্থান শুধুমাত্র ২টি স্বতন্ত্র ভ্যালু (0 এবং 1) ধরে রাখতে পারে। একটি বাইনারি ডিজিটকে বলা হয় বিট (বাইনারি + ডিজিট) । আমরা ৮ বিট একসাথে সংরক্ষণ করি এবং একে বাইট বলি।
যেহেতু একটি বিট ২টি ভ্যালু ধারণ করতে পারে, 0 বা 1, আপনি 2^n গণনা করে সম্ভাব্য মানের সংখ্যা গণনা করতে পারেন যেখানে n হলো বিটের সংখ্যা। প্রতি বাইটে ৮ বিট থাকলে, একটি ছোট পূর্ণসংখ্যা যার জন্য 2 বাইট বরাদ্দ করা হয় অর্থাৎ 216 (65,536) সম্ভাব্য 0 এবং 1 এর সংমিশ্রণ সংরক্ষণ করতে পারে। যদি আমরা সেগুলোকে নেগেটিভ এবং পসিটিভ ভ্যালুর মধ্যে ভাগ করি, তাহলে সংক্ষিপ্তভাবে ডেটা রেঞ্জ -32,768 থেকে +32,767 হয়।
আপনার প্রিয় ল্যাঙ্গুয়েজে একটি প্রিমিটিভ ডেটা টাইপ কতটুকু জায়গা লাগে তা আপনি সহজেই খুঁজে পেতে পারেন, Go-এর জন্য, এখানে একটি টেবিল সহ একটি ডকুমেন্ট রয়েছে: https://www.tutorialspoint.com/go/go_data_types.htm
Data Structure and Why We Study Them
ডেটা স্ট্রাকচার প্রিমিটিভ ডেটা টাইপ থেকে আলাদা, কিন্তু সেগুলো তাদের মতই এই অর্থে যে এটি নির্দিষ্ট পূর্বনির্ধারিত পদ্ধতিতে একই ডেটা ধারণ করে (স্ট্রাকচার)।
যখন আমরা ডেটা স্ট্রাকচার এবং অ্যালগরিদম অধ্যয়ন করি, তখন আমরা স্পেস (RAM) এবং প্রসেসিং (CPU) এফিসিয়েন্সি সম্পর্কে কথা বলি। প্রসেসিং শক্তি এবং মেমরি উভয়ই লিমিটেড। তাই আমাদের জিনিসগুলোকে অপ্টিমাইজ করা দরকার যাতে এটি সর্বনিম্ন পরিমাণ স্পেস এবং প্রসেসিং টাইম নেয়। আপনি চান না আপনার ল্যাম্বডা ফাংশন চিরতরে চলমান থাকুক, তাই না? আপনি চান এটি সর্বনিম্ন সময় নেক এবং সর্বনিম্ন পরিমাণ স্পেস নেক, তাই না?
Types of Data Structures
আমাদের RAM হলো মূলত মেমরির সেল যা নীচের চিত্রে মতো দেখতে।

Linear Data Structures
1. Array
- একটি অ্যারে (Array) মূলত অনুরূপ ভ্যালুগুলোর একটি লিস্ট।
- একটি অ্যারের এলিমেন্টগুলো কন্টিগুয়াস মেমরি ব্লকে সংরক্ষণ করা হয়।
- সমস্ত এলিমেন্টের একই ধরনের ডেটা টাইপ থাকতে হবে।
- অ্যারের একটি নির্দিষ্ট লেংথ রয়েছে।
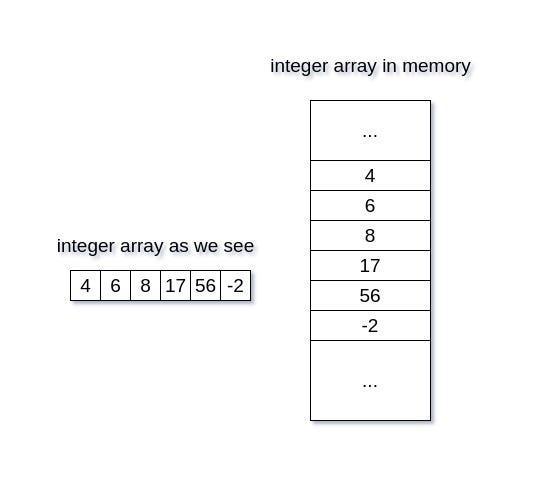
আপনি ছবিতে দেখতে পাচ্ছেন, RAM এর একটি সেকশন রয়েছে যেখানে সমস্ত ডেটা একটি কন্টিগুয়াস মেমরি ব্লকে সংরক্ষণ করা হয়।
তাই পাইথন লিস্ট সত্যিই একটি অ্যারে নয় কিন্তু এক হিসাবে গণ্য করা হয়। অনুরূপ ভ্যালু নিয়ে কাজ করা সর্বদা দ্রুত হয়, এই কারণেই আপনি numpy কে অনুরূপ ডেটা টাইপ ব্যবহার করতে দেখেছেন একটি নতুন অ্যারে ডিফাইন করার জন্য।
2. Linked List
- অ্যারের মতো লিংকড লিস্টও একটি ডেটা স্ট্রাকচার, যেখানে এলিমেন্টগুলো কন্টিগুয়াস মেমরি লোকেশনে সংরক্ষণ করা হয় না।
- একটি লিংকড লিস্ট ডেটা স্ট্রাকচারে, আমাদের সাধারণত একটি পেলোড ভেরিয়েবল থাকে, এক বা দুটি পয়েন্টার ভেরিয়েবল যা লিস্টের পরবর্তী এলিমেন্টের দিকে নির্দেশ করে।
- কন্টিগুয়াস মেমরিতে সংরক্ষিত না হওয়ায়, এটি RAM এর যে কোনো জায়গায় মেমরি বরাদ্দ করার ফ্লেক্সিবিলিটি দেয়, যা উপকারী এবং অ্যারের চেয়ে স্মার্টভাবে এভেইল্যাবল স্পেসের সুবিধা দিতে পারে।
- লিংকড ভেরিয়েশনগুলো হলো সিঙ্গেললি লিংকড লিস্ট, ডাবললি লিংকড লিস্ট, সার্কুলার লিংকড লিস্ট। সিঙ্গেললি লিংকড লিস্টে পরবর্তী এলিমেন্টের জন্য শুধুমাত্র একটি পয়েন্টার থাকে তবে ডাবললি লিংকড লিস্টের পরবর্তী এলিমেন্টের পাশাপাশি পূর্ববর্তী এলিমেন্টেটির জন্য একটি পয়েন্টার থাকে।
- প্রসেসরের জন্য কাজের সিডিউল নির্ধারণের সময় সার্কুলার লিংকড লিস্ট ব্যবহার করা হয়, যদি একটি কাজ IO বা নেটওয়ার্ক রিসোর্সের জন্য অপেক্ষা করে, তখন পরবর্তী কাজগুলো আসে।
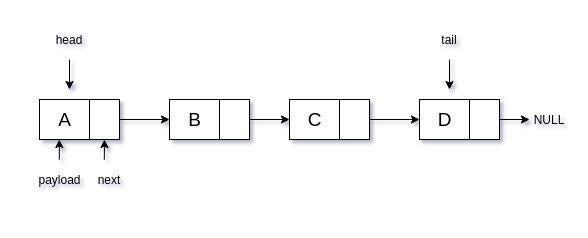
এখন যেমন আপনি অ্যারের ক্ষেত্রে দেখেছেন, লিংকড লিস্টের প্রতিটি এলিমেন্ট র্যামের যেকোনো জায়গায় থাকতে পারে।
এর একটি খারাপ দিকও রয়েছে, আপনি একটি অ্যারের মতো লিংকড লিস্টের কোনো আইটেম সরাসরি অ্যাক্সেস করতে পারবেন না।
3. Queue
- কিউ হলো একটি ডেটা স্ট্রাকচার যা স্টুডেন্টদের মর্নিং অ্যাসেম্বলির কিউয়ের সাথে রিলেট করা যেতে পারে। যদি পুরো কিউর ক্লাসে যেতে হয়, কিউর প্রথম ছাত্রকে প্রথমে যেতে হবে; তারপর অন্যান্য ছাত্রদের।
- একইভাবে, কিউতে, আমরা কিউর শেষে ডেটা যোগ করতে পারি এবং এটিকে শুরু থেকে সরিয়ে দিতে পারি।
- কিউকে FIFO (ফার্স্ট ইন ফার্স্ট আউট) ডেটা স্ট্রাকচারও বলা হয়। এলিমেন্ট (ডেটা) এর দৃষ্টিকোণ থেকে দেখলে, ডেটা প্রথমে প্রবেশ করে, তারপর প্রথম ডেটা বের হয়।
- শুধুমাত্র টাস্ক কিউগুলো মেনেজ করার জন্য সফ্টওয়্যার লেখা হয়েছে, যা ডিস্ট্রিবিউটেড কম্পিউটিংয়ে অত্যন্ত ব্যবহৃত হয়। RabbitMQ হলো এমনই একটি সফ্টওয়্যার।
4. Stack
- Stack নামটা শুনার পরে কি আপনার StackOverflow বা stacktraces এর কথা মনে পরেছে? হ্যাঁ, তারা উভয়ই সেম স্ট্যাক ডেটা স্ট্রাটারের সাথে সম্পর্কিত।
- স্ট্যাককে, প্লেটের একটি স্ট্যাকের সাথে রিলেট করা যেতে পারে, প্রথমে একটি স্ট্যাকে কিছু এড করার জন্য আপনি এলিমেন্টটি টপে রাখেন, আর রিমুভ করার সময়, আপনি টপ থেকে সরিয়ে নেন। যদি আপনাকে n-1 এলিমেন্ট অ্যাক্সেস করতে হয়, আপনাকে প্রথমে সমস্ত ইন্টারমিডিয়েট এলিমেন্টগুলো অ্যাক্সেস করতে হবে।
Non-Linear Data Structures
- Graph
- আপনি কি ডিসক্রিট ম্যাথমেটিক্সে গ্রাফ থিওরি সম্পর্কে শুনেছেন? হ্যাঁ, তারা সেমই। যদি না শুনে থাকেন তবে কিছু ইউটিউব ভিডিও দেখে ফেলুন।
- একটি গ্রাফ; নোড এবং শীর্ষবিন্দু বা ভারটিসেস নিয়ে গঠিত।
2. Tree
- ট্রি এক ধরনের গ্রাফ। ট্রি হচ্ছে গ্রাফের একটি উপসেট যেখানে গ্রাফ ডিরেক্টেড থাকে। একটি ট্রির প্রতিটি ইমপ্লিমেন্টেশন তার ব্যাকরণে ভিন্ন।
- নির্দিষ্ট ডেটা স্ট্রাকচারের অনেক ভেরিয়েশন রয়েছে, যেমন বাইনারি (Binary) ট্রি, এভিএল (AVL) ট্রি, রেড-ব্ল্যাক (Red-black) ট্রি, হিপস (Heaps) ইত্যাদি সহ একাধিক ধরণের ট্রি রয়েছে।
এটি কোনওভাবেই ডেটা স্ট্রাকচারের একটি সম্পূর্ণ তালিকা নয়, কিছু ডেটা স্ট্রাকচারকে একত্রে মিশ্রিত করে তৈরি করা যেতে পারে, হ্যাশ ম্যাপ এমন একটি ডেটা স্ট্রাকচারের উদাহরণ যা খুবই এফিসিয়েন্ট বলে পরিচিত। তার উপরে, কিছু ডেটা স্ট্রাকচার অন্যান্য ডেটা টাইপ ব্যবহার করে প্রয়োগ করা যেতে পারে যেমন স্ট্যাক এবং কিউ, অ্যারে বা লিংকড লিস্ট ব্যবহার করে প্রয়োগ করা যেতে পারে।
প্রতিটি ডাটা স্ট্রাকচারের নিজস্ব তাৎপর্য রয়েছে এবং তাদের মধ্যে একটি সেরা ডাটা স্ট্রাকচার রয়েছে।
Operations of Data Structures
কিছু জেনেরিক অপারেশন আছে যা আমরা অনেক ডেটা স্ট্রাকচারে করতে পারি। আসুন এক এক করে তাদের দিকে তাকাই।
1. Add/Insert/Push/Enqueue
- আমরা পূর্বনির্ধারিত দৈর্ঘ্যের অ্যারেতে একটি নতুন আইটেম যোগ করতে পারি, আমরা তাদের ইনসার্টিং বলি। সাধারণত পুশ টার্মিনোলোজি ব্যবহার করা হয় যখন আমরা স্ট্যাকের মতো ডেটা স্ট্রাকচারের শেষে এড করি।
- ইনসার্টের একাধিক ভেরিয়েশন থাকতে পারে: add, addFirst, addLast, addByIndex
- ভেরিয়েশনগুলো ডেটা স্ট্রাকচারের প্রকৃতির উপর নির্ভর করে। যেমন, আপনি একটি লিংকড লিস্ট বা অ্যারের প্রথমে ইনসার্ট করতে পারেন, কিন্তু আপনি একটি স্ট্যাকের মধ্যে ইনসার্ট নাও করতে পারেন।
2. Get/Access
- ভেরিয়েশনের মধ্যে getByIndex অন্তর্ভুক্ত।
- আপনি একটি লিংকড লিস্টে ইনডেক্স পেতে পারেন না।
3. Search/Traverse
- আমরা যে অ্যালগরিদম ব্যবহার করি তার উপর নির্ভর করে সার্চিং ভিন্ন হতে পারে। আমরা লিনিয়ার ফ্যাশনে একটি অ্যারে সার্চ করতে পারি, তবে আমরা বাইনারি সার্চ নামক কিছু ব্যবহার করতে পারি যেখানে আমরা যে ভ্যালুটি সার্চ করছি তার উপর নির্ভর করে অ্যারেকে দ্বিখণ্ডিত করে অ্যারের অর্ধেকটি এলিমিনেট করে ফেলি।
- বাইনারি সার্চের পূর্বশর্ত হলো ডেটা স্ট্রাকচারকে সর্ট করতে হবে।
4. Remove/Delete/Pop/Dequeue
- যখন আমরা একটি স্ট্রাকচারের শেষ থেকে একটি এলিমেন্ট রিমুভ করি, তখন আমরা একে পপিং বলি। কিউয়ের ক্ষেত্রে, এটিকে ডিকিউ বলা হয়।
- ভেরিয়েশনের মধ্যে deleteFirst, deleteLast, deleteByIndex অন্তর্ভুক্ত থাকতে পারে।
5. Modify/Edit/Update
- প্রতিটি অপারেশনের জন্য একটি নির্দিষ্ট সময় লাগে, যা আমি একটি পোস্টে আলোচনা করব যখন আমি অ্যালগরিদম নিয়ে আলোচনা করব।
কোথায় থেকে ডেটা স্ট্রাকচার শিখবেন এবং অনুশীলন করবেন
আমি কোনোভাবেই DSA-এর গুরু নই, কিন্তু আমি সম্প্রতি freeCoceCamp-এর মাধ্যমে এই রিসোর্সটি খুঁজে পেয়েছি।

https://youtu.be/zg9ih6SVACc
অবশেষে, যদিও এটি সরাসরি DSA এর সাথে রিলিটেড নয়, তবে একটি ম্যাথেমেটিক্যাল ব্যাকগ্রাউন্ড থাকা সবসময়ই ভালো এবং আমাদের এনালিটিক্যাল থিংকিং করতে সহায়তা করে। সেই জন্য, যদি আপনার ম্যাথেমেটিক্যাল ব্যাকগ্রাউন্ড না থাকে, তাহলে আমি [Project Euler](https://projecteuler.net/archives) থেকে সমস্যা সমাধানের পরামর্শ দেব। সমস্যা সমাধানের প্রক্রিয়ার মধ্য দিয়ে যাওয়া আপনাকে একটি বেটার-অপটিমাইজড অল্টারনেটিভ সন্ধান করতে বাধ্য করবে যা শুধুমাত্র ঐ বিষয়ের উপর গবেষণা করে হওয়া সম্ভব।